Related Articles
- Scaling NMIS Polling
- Scaling NMIS polling - how NMIS handles long running processes
- Configuration Options for Server Performance Tuning
Configuration items
NMIS runs a daemon to periodically obtain the nodes information, and other maintenance jobs that need to be done (to calculate metrics, cleanup jobs, run the plugins, etc.).
The main process - the nmis scheduler - runs a loop and checks which jobs need to be done. It will add these jobs into a queue, and it will fork worker processes that will run these jobs.
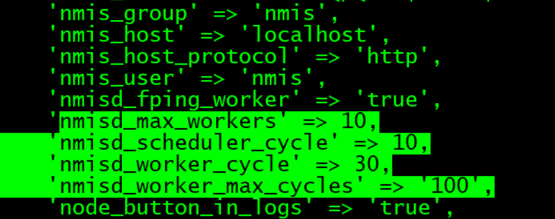
The number of workers is set in the parameter nmisd_max_workers:
nmisd_max_workers
This means the maximum number of worker processes that the nmis main process will be able to start.
This parameter takes by default a value of 10. But this value is too big for a small network. Can be adjusted based on the number of nodes:
| Number of nodes | Number of threads |
|---|---|
| 120 | 3-4 |
The nmis scheduler will run in a loop. When an iteration is finalised, the process will sleep for nmisd_scheduler_cycle seconds. This value is 10 by default, but it can be modified.
'nmisd_scheduler_cycle' => 10,
There are a couple of configuration items to modify the lifecycle of the forks.
'nmisd_worker_cycle' => 30, 'nmisd_worker_max_cycles' => 100,
nmisd_worker_cycle is the number of seconds the process will sleep if it doesn't have any job to perform.
Every time a worker performs a job, a cycle counter is increased. It is possible to change the default behaviour so the worker is killed every N cycles. Another process will be started by the parent once the child process reaches the max cycles, if the number of children processes doesn't reach the max_workers. It will prevent a worker memory get too big. This number can be adjusted, as, if it is too low, there is a cost associated in killing and starting a new process. Can be changed in nmisd_worker_max_cycles. Check OMK-8536 - Getting issue details... STATUS for more details in tests with this value.
Go to usr/local/nmis9/conf/ Config.nmis