Overview
NMIS 8.6.6 introduces a new feature called 'polling failover' for monitoring hosts that are reachable by multiple/redundant paths. This page briefly describes this feature.
Best Current Practices and Alternatives
Most environments that deal with multi-homed nodes use aside 'loopback' addresses for monitoring, and let their routing infrastructure handle any failover, convergence and re-routing required.
This makes path changes transparent to NMIS and thus minimises negative effects of such a change.
If that is not an option in your environment, then you may want to use NMIS' new feature for explicit polling failover.
Node Configuration for Polling Failover
NMIS normally communicates with a node exclusively using the configured host address/name.
If this address becomes unreachable, then NMIS attempts to switch over to the host_backup address on the fly and continues polling like normal.
To enable this capability, simply add your host's secondary address/name in the node configuration dialog (like in the screenshot below) and run a type=update operation:
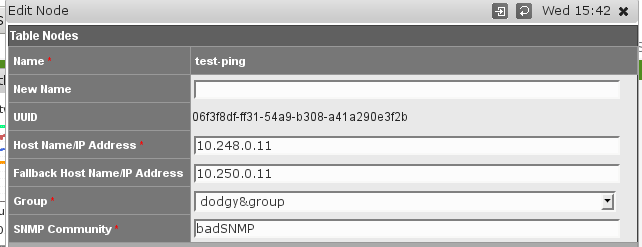
As long as at least one address remains reachable, NMIS will be able to poll the node.
Should the primary address become inaccessible, then NMIS switches polling over to the fallback host_backup address, and raises an event called 'Node Polling Failover'; the node is also flagged as being in 'degraded' state. This event is cleared if and when the primary address becomes reachable again.
When NMIS polling has fallen back to the secondary address, the node's status shows "Node Polling Failover" as one of the reasons for the degraded state, like in the screenshot below:

If all addresses of the node are unreachable, then NMIS flags the node as 'unreachable'.
In NMIS 8.6.7 and newer, the "Node Polling Failover" event is also raised if the primary address becomes unreachable (i.e. if fpingd detects it as unpingable). Additionally, a separate event "Backup Host Down" is raised if the host_backup address is unreachable. Either events' presence causes the node to be flagged 'degraded'.
Known Limitations
- NMIS currently pings both addresses in parallel.
- Only one set of Ping (Response Time, Packet Loss) statistics is recorded.
The Ping statistics will switch transparently from primary to fallback address if and when the primary becomes unreachable. - Polling failover is not available for WMI data collection.
- Polling failover is not available for Service Monitoring.
- The polling failover decision is made for each ping, collect or update operation, regardless of previous results.
Whenever an SNMP connection needs to be opened, NMIS tries the primary address first, and if that fails, switches to the secondary.
This can introduce undesirable delays to a node's polling, but minimises latency for switching back when the primary address becomes accessible again.