NMIS (acronym for Network Management Information System) is an open-source network management system that was first released in 1998. Originally written by Keith Sinclair and with later substantial input from Eric Greenwood, the intellectual property for NMIS was purchased by commercial open source software company Opmantek in early 2011 under a stated commitment to keep "NMIS free and lead the community to rapidly advance the product". NMISv8 was released by Opmantek shortly after and remains free and open source. NMISv9 is currently (as at April, 2020) in the final stages of development. NMIS is a complete network management system which assists with fault, performance and configuration management, providing performance graphs and threshold alerting as well as highly granular notification policies with many types of notification methods. Additional modules and support provided by Opmantek are available to extend the capabilities of NMIS. NMIS monitors the status and performance of an organization's IT environment, assists in rectification and identification of faults and provides valuable information for IT departments to plan expenditure and IT changes.![]() What is NMIS?
What is NMIS?What does NMIS do?
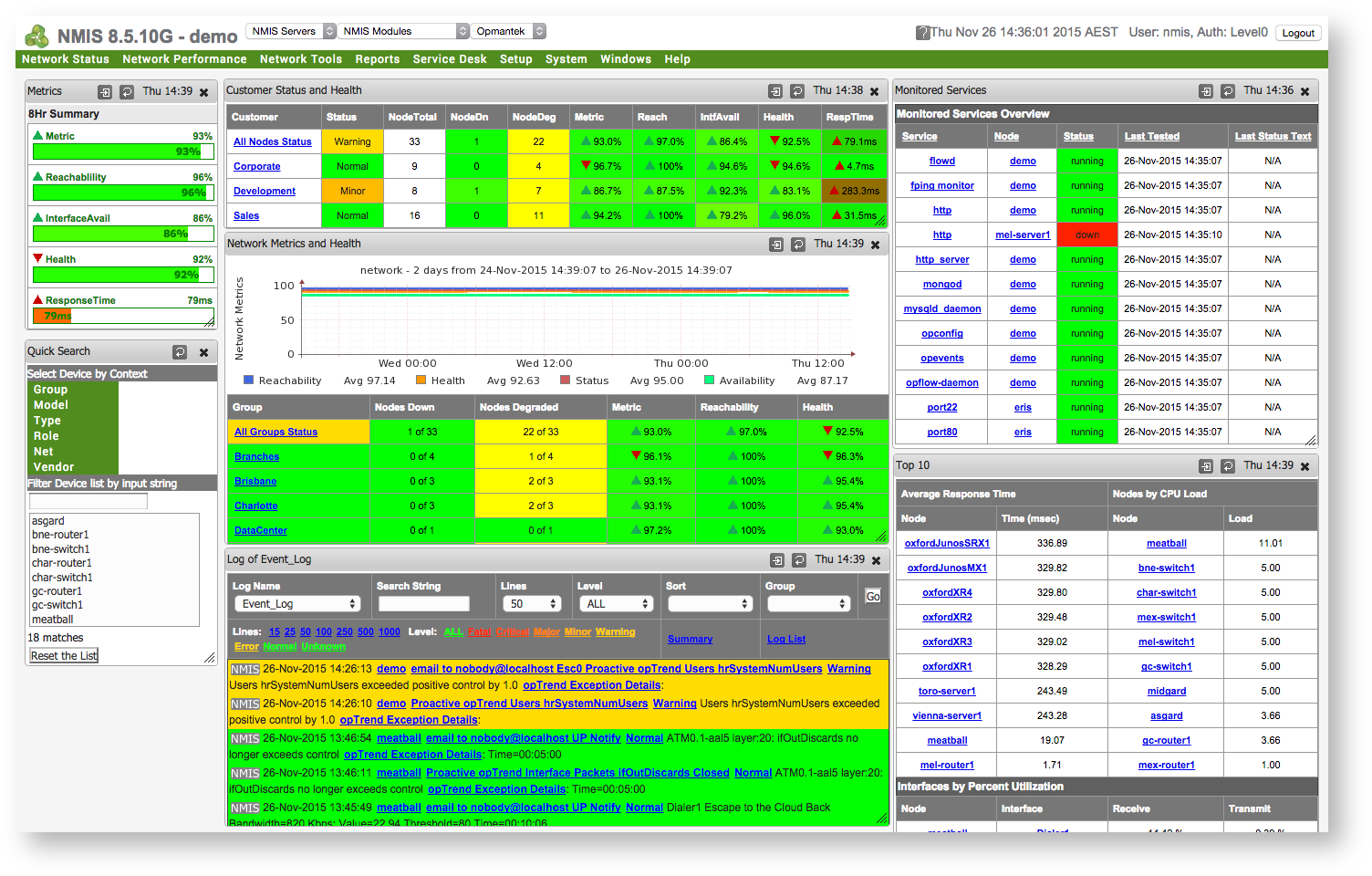
But Why?
NMIS performs multiple network management functions from the OSI Model and International Organization for Standardization FCAPS model, these being - Fault, Configuration, Accounting and/or Administration, and Performance. These metrics provide valuable capabilities and features for fault and performance management, which in turn are useful for many other aspects of network and business management. NMIS is very popular within Telecommunications carrier organizations and Managed Service Providers (MSP's) and is used by IT staff as a key business management and improvement tool.
Features?
The NMIS business rules engine classifies events on their business impact, not just the technical nature. The rules engine is extremely powerful; however, it can be configured in minutes for a network with a small number of devices to hours for networks with large numbers of devices.
NMIS currently supports 10,000 vendors out of the box. The simple set-up allows for network management to occur quickly and can easily integrate new technology.
Operations can see how device performance is impacting the health of a single device, a group of devices or of the whole network. Add opCharts to see these impacts on topological maps.
NMIS measures a baseline of availability, response time and performance, and automatically shows the changes when compared to the previous period baseline. Add in opTrend to intelligently identify outliers to your baselines.
From the largest distributed global environments down to a single office implementation, NMIS handles the data, rules, and presentation. If you add in opHA there is no limit to what you can manage in a single pane of glass.
NMIS allows for customised alert escalation to suit your business. Escalate events based on your organisational structure, operational hours or chain of command. Add opEvents to even automate the event remediation of event management.
How does it work?
NMIS uses a single poll (usually but not necessarily SNMP) for performance and fault data, which reduces the bandwidth of the network management traffic and increase the performance of the network management system. The returning data creates real-time performance monitoring and graphing. When NMIS probes are deployed throughout the network, the network can be managed easily to avoid bottlenecks and enable zero cost redundancy. Both the front and back ends of NMIS are highly extensible and features are easy to add. Custom statics can be gathered for any metric available on a device.
How is it built?
NMIS has been developed in Perl and runs natively on Linux, performing best as a 64-bit multithreaded application. It is commonly used on 64bit Red Hat Enterprise Linux, or other F/OSS equivalents such as CentOS, Debian and Ubuntu. The software is available online as source code (with installer script) or as a Virtual appliance. The Virtual Appliance is compiled as a .OVA image and can be run through any major virtualization product such as VirtualBox or VMWare. It comes with NMIS, Open-AudIT, CentOS and Apache installed and requires no additional configuration.
Licensing
Licensed free of charge under the GNU General Public License. Support contracts provided by Opmantek.
Feature Summary
| Performance Management | Faults and Events | Configuration |
|
|
|
| Real-time monitoring | Operational Tools | Management Reporting |
|
|
|
| Extensive list of supported devices | Business Rules Engine | Notification and Escalation |
|
|
|
| Distributed Monitoring | Notification | Ease of Implementation |
|
|
|
| Scalability | ||
| ||