Some devices don't like to be managed in a conventional way. Think IP Phones. Typically they won't have SSH or SNMP running, so discovery won't have much of an idea what they are. No credentials, no useful open ports, no information.
Here's where an Enterprise license pays dividends. You will need to know a port that the target IP Phone (or any device, really) listens on and it's protocol (TCP or UDP). Once you know that, in your discovery add this to either Custom TCP Ports or Custom UDP Ports. Once catch - make sure to include the ports that exist by default for the Discovery Scan Options you are using. These are already listed, however will be 'greyed out', see below screen shot. IE, if your IP Phone listens on TCP 5001, make your port list 22,135,62078,5001

Once that has been done add a new Rule. Menu → Manage → Rules → Create Rules. Set the port to your IP Phones listening port and set the type. See below.

From now on, whenever you run this discovery, if a device responds on your designated port it will be set to type = ip phone.
Easy ![]()
As at October 2020, we have released a new version of Open-AudIT using version 4.0.0.
Why the major version bump?
Well our underlying build infrastructure and libraries have changed in an incompatible way.
This new version is not able to be installed with older Opmantek applications that are designed to talk to NMIS8, hence the major version number increase to 4.0.0.
Wait - my applications won't work, what?
Unfortunately this is a breaking change. If you are using other Opmantek applications on the same server, you will need to upgrade them all at the same time, including upgrading to NMIS9.
New License Required (perpetual license only)
A new license will be required if you have a perpetual license. Subscription licenses are unaffected. Contact Opmantek if you require a new license.
Application wise, what has changed for me?
Not much really. Most of the changes are behind the scenes. Having said that, there are a few minor front end changes, as detailed in the Release Notes for Open-AudIT v4.0.0.
We have disabled Open-AudIT - NMIS integration for the moment. This is one component that we have to rework in order to be compatible. This is coming ASAP. We have implemented the ability to import and export to and from NMIS as below (all available using the GUI, see Manage → Devices → Import from NMIS). What we don't have is the ability to sync between NMIS and Open-AudIT.
Community
- Auto Import from NMIS 8 using locally loaded and parsed Nodes.nmis (Linux only) and also uploading a Nodes.nmis file (Windows and Linux).
- Auto Import from NMIS 9 on Linux using the local command line (Linux only).
- Manual export to NMIS 8 - you select the devices and it'll give you a CSV and instructions to import. (Windows and Linux).
Professional / Enterprise
- Auto Import from NMIS 8 using locally loaded and parsed Nodes.nmis (Linux only).
- Auto Import from NMIS 9 on Linux using the local command line (Linux only).
Should I upgrade?
No, but maybe you should migrate. That will depend on if you are using NMIS on the same machine (hence Windows users will be unaffected). If you're not using NMIS (or any other Opmantek applications) on the same server, migrate away! If you are using NMIS on the same server as Open-AudIT, to get to version 4.0.0 you will need to be running NMIS9 and any associated and migrated Opmantek products (opCharts, opReports, et al). If you migrate any Opmantek applications for NMIS9, you will need to migrate them all. We do encourage users to migrate to version 4.x as soon as you can (bearing in mind the NMIS9 requirements).
How do I migrate (and why is this different to an upgrade)?
Our installer will not allow you to upgrade from 3.x to 4.x on Linux. This is in part because when you change to 4.x, you must uplift all other Opmantek applications and we want to make sure you knowingly choose to do so. So, how do you do this? It's actually very easy. Stop the OMKD daemon, move the /usr/local/omk folder out of the way, and start the 4.x installer. NOTE - If you have NMIS 8 installed, but only Open-AudIT, DO NOT UPGRADE, it will break. Again - NMIS 9 only (at least for now).
# Stop the daemon sudo systemctl stop omkd # Move the old install out of the way (do *not* delete it) sudo mv /usr/local/omk /usr/local/omk.old # Run the installer sudo ./tmp/OAE-Linux-x86_64-release_4.0.0.run # Copy the original configuration files back sudo cp -r /usr/local/omk.old/conf/* /usr/local/omk/conf/ # Convert those original files to JSON sudo /usr/local/omk/bin/opcommon-cli.exe act=convert_json_dir dir="/usr/local/omk/conf/" # Restart the OMKD daemon so it uses the newly converted files sudo systemctl restart omkd
After doing the above, if Open-AudIT doesn't acknowledge you have a license, copy the encrypted string from /usr/local/omk.old/conf/opLicense.nmis and paste into the text field at http://YOUR_SERVER/omk/opLicense (use the Enter a License Key button).
On Windows, there is nothing to do, just run the installer.
What about Windows users?
Windows users are essentially unaffected. Opmantek does not release or support any other products for Windows. Our plan is to get a Windows release out ASAP. This will also be version 4.0.0.
What will happen to us version 3.x users?
We plan to focus development going forward on the 4.x series, so that's where major new features will be introduced. We won't completely forget version 3.x users though. Any unpatchable security issues will be back-ported.
Is Open-AudIT Community affected?
Basically, no. Professional and Enterprise build their feature sets on top of Community. There have been a couple of very minor changes to Community that don't affect users (ie, we check and parse an additional config file from Enterprise because that changed). Minor stuff like that. As a result, when you install Professional or Enterprise you will see version 4.0.0 in the title bar, however if you change to the Community GUI you'll see version 3.5.1. Both the version 4.x and 3.x streams of Professional and Enterprise use the same version of Community (as said, currently 3.5.1). Eventually (when we discontinue support for the 3.x series of Professional / Enterprise) we will increase the Community version to match the 4.x series.
Some of you may have read about some recently reported vulnerabilities within Open-AudIT. This post seeks to explain and clarify these, along with detailing further fixes implemented.
The vulnerabilities fall into one of two categories - cross site scripting and code execution.
For the record, I do consider these to be vulnerabilities, however I find them to be quite contrived. In all cases you must be logged into Open-AudIT (no unauthenticated issues have been found) and in the case of the code execution bugs, you have to also be an Admin in Open-AudIT. For me personally, I consider that if you're an Admin you can already see the device credentials and could therefore run any code you like using a shell anyway. As said - I do consider these as vulnerabilities, but not earth shattering. Actually more concerning is the XSS vulnerability (of the two). A logged in Open-AudIT user could craft a link and send it to a more privileged Open-AudIT user, who opens it and can have arbitrary JavaScript run in their browser. Maybe a privilege escalation issue could occur in the application. If you have users who you do not trust that are using Open-AudIT, I think you have bigger problems. Again, yes it is a vulnerability. I just consider it minimal in the grand scheme of things.
So what are we doing to address these? Well obviously we have released new code that addresses all the reported issues. If you do not wish to upgrade and are a supported customer, Opmantek will also provide assistance regarding patching your existing install. Really though - just upgrade. We have made other improvements besides these fixes and it is well worth your time.
What have we done in addition to this? We have been through user input and sanitized it against known types, for a start. IE - If you change the configuration log_level value, it must be an integer. Previously we did do some validation, but it turns out not enough (for contrived issues). Another example is the user supplied SQL for groups, queries and widgets. From now on, we reject any SQL that contains INSERT, UPDATE or DELETE clauses (and variations there-of). Again - if you're letting a user create queries you should be trusting them to do so in the first place. But we have tightened this up regardless. For other items such as attributes, files and scripts we have also now restricted what we accept in various fields. These restrictions may possibly affect the odd user, but should not be overly restrictive and no existing entries will be changed. We also found some minor cross site scripting issues (un-sanitized output) in some standard templates. We have now escaped these and as a result they may look ugly, but they are safe. And if you manage to see one of these, looking pretty is not what I am concerned with, I'm more interested in "why are you seeing that".
So there it is - nothing major (in my opinion) but I feel if you are forewarned, you are armed.
As always, please upgrade to the latest available release for these fixes along with many other new improvements.
The Release Notes pages detail what changes for each release and I would encourage you to read them every time we release.
If you have any questions or concerns, feel free to reach out to us here at Opmantek. I recommend the Questions site so everyone else can also see your question and our response.
Mark Unwin.
Hi All,
Release 3.3.0 of Open-AudIT has some amazing new features, read on for the details. The release notes are available as usual, here - Release Notes for Open-AudIT v3.3.0.
Configurable Device Columns
From 3.3.0 onward, when you view the list of devices (Manage → Devices → List Devices), you'll notice a small additional control on the upper right. Click it and you'll see a list of available columns you can display. Click a column name and it will appear. Click a bold column name and it will disappear. If you want that set of columns as your default, click "Save as Default" and every time you view the device list, those will be your default columns. You can also click "Reset to Default" (if your columns are different) to reset them. The default list of columns is in the configuration under the name devices_default_display_columns. If you are seeing a n unacceptable slow down viewin gthe page, you might wish to limit the retrieved (but not displayed) columns. This is also in the configuration under the name devices_default_retrieve_columns. See the screenshot below.

Device Components
Also on the Devices list page, you'll notice a bar at the very top with a drop down arrow on the right. Click the arrow and you'll see a list of component types. Click one to see a list of all those items. Be aware this list may be very large so we restrict it to the first "database_show_row_limit" (configuration item) entries. Increase that number to see more. At this stage we have not implemented a GUI for paging, but it is available using the API (or adding to the URL), by specifying limit and offset. So a valid URL might be (for instance) http://SERVER/omk/open-audit/devices?sub_resource=software&limit=200&offset=100. See the API documentation for more information - The Open-AudIT API. The following pages allow you to click links to see this specific entries details, all those entries on a device or the device details itself.


Comparing Your Database Schema
There is a new entry under menu → Admin → Database called Schema Compare. Running that will show you the schema as it is in your running database and compare it to the schema as shipped with Open-AudIT. If there are any differences, just post them to Questions and we can help you out. For supported customers, just log a support request and we'll assist ASAP.
Change Log Improvements
Time has been spent to minimize false positive Change Logs being generated. As well as that, we have added two buttons on the Device Details screen (under the left side Actions menu) to remove Change Logs and remove Audit Logs. Using these may help improve database performance where these records are not required. Don't forget you can always clear the entire tables using menu → Admin → Database → List Tables, clicking either table and hitting the Delete button. And don't forget about our new configuration items for keeping non-current items and creating change logs. More information on these can be found here - Device SubSection Data Retention Options.
Deleting Devices
There is now a configuration item named device_auto_delete. If set to 'y' (it is set to 'n' by default) when you change a device's status (either individually or using Bulk Edit) you will get a regular warning "Are you sure?" and if you answer yes, the device and all it's details will be completely removed from the database. Not just flagged with a status of deleted.
New Discovery Process and Improvements
With the coming release of Open-AudIT 3.3.0 we have implemented a new discovery process that scales even better than previously. Even faster discovery times!
The Discovery Queue
With 3.3.0 we have changed to using the discovery queue, not on a per discovery basis as previously, but on a per IP basis. From 3.3.0 onwards, when you click "Execute Discovery", the following happens behind the scenes:
- The server starts a script that calls /util/queue and instantly returns to the web user (or the API user). It starts the shell script and does not wait for a response before returning.
- The user then continues on using the web/API as per normal.
- The shell script calls util/queue - this endpoint only accepts requests from localhost. The resulting function does the following:
- Check the config for the queue limit. If this has been reached, exit. If it has not been reached, continue.
- Pop an item from the queue (locking the queue table as it does so). The item is read from the database, then deleted. If no queue items exist, exit.
- Spawn another script to request util/queue.
- Execute the item - which on the first time is always "run discovery on subnet".
- When finished, return to #1.
There are (currently) two types of queue entries. The overall discovery entry, and an entry for each IP to be scanned. The second entry is created by the first. So we run the initial discovery, and for each IP we need to scan (that responds, if that option is chosen), we create another entry to scan that device.
We no longer use the discover_subnet.sh or discover_subnet.vbs scripts at all. We now call Nmap directly from within the Open-AudIT code, which frees us up to have one and only one routine (versus a bash and vbscript). It also makes it easier to code - PHP has much easier to use text parsing than bash and vbscript (in my opinion).
Because of the above, we have created a new configuration item called "discovery_limit" and set it to 20 by default. This means when a discovery is run, it will spawn up to 20 processing instances in parallel. Because of this parallel processing of target IPs, discovery is $discovery_limit times faster. Well, not quite, but you get what I mean. The old way ran a discovery and for each target, sequentially, started a scan. Several scans were run at once, but it was still waiting for an Nmap scan, before handing off to PHP to complete the rest. The new way completes the initial scan and loads all resulting devices into the queue to be processed in parallel. At the end of the day, it's just so much faster.
Sudo SSH Key and Password
Previously we only had support for an SSH Key that used a password, but where that password was also used for sudo. That is obviously not optimal, so as at 3.3.0 you can add a specific ssh key password and a sudo password.
Additional Nmap Option
We have also added a new option to discovery scan options - open|filtered. Previously we used the "filtered" column to check for open|filtered. This change aligns the discovery scan options with Nmap return strings.
Auditing Time Reduction When Using sudo
When auditing a device using sudo, we no longer have to wait for the configuration item discovery_ssh_timeout (previously 300 seconds) to timeout. We now check every 2 seconds for our response and when received, proceed. This has made another large difference to audit times when using sudo.
Windows Users Apache Service
As well as this, there has been a change targeted specifically to Windows Open-AudIT Servers. Because of the issue's we have run into using the default service account, you will now get a big warning stating you should change the service account to a "real" account. This is because by default the service account cannot access network resources. IE - copy the audit script to thew target and run it. The "old" way of running the script on the Open-AudIT server itself and specifying the target still works and is enabled by a config item - discovery_use_vintage_service, which is set to 'n' by default. One reason for this is that the discovery script contains sections that do not and can not work remotely. Think starting an executable. That won't work as WMI can target the remote machine, but running an executable from the audit script would run it where the script is running - the Open-AudIT server.
The Default Network Address
Because of our new way of running discovery, we no longer need to set the Default Network Address. The scripts are run on the target devices and create a file (as opposed to submit_online=y). That file is then copied to the server and processed, rather than submitted using the URL (that was created from the default_network_address). The only reason to set the Default Network Address for Discovery is if you're using discovery_use_vintage_service. The now normal use of this is only for the "Audit My PC" functionality.
Auto Delete our Audit Script
Now when discovery runs, the audit script deletes itself on the target, hence we leave nothing present on the target device.
No More "New" Devices Where We Have No Information
We have added a new configuration option called match_ip_no_data. If we discover a device and that IP is already in the database and we have no audit data about that device, assume it is the same device, so do not create another (usually duplicate) device.
SNMP Route Retrieval
We now retrieve the first (configuration item discovery_route_retrieve_limit) routes from a device when using SNMP.
And there's even more improvements. Make sure you read the Release Notes for Open-AudIT v3.3.0 to stay across it all.
Mark Unwin.
With the release of Open-AudIT 3.3.0, we've introduced a great new feature users have been asking for, for a while now - selectable columns on the List Devices page!
As of 3.3.0, when you go to menu → Manage → Devices → List Devices, you will see a new button on the top right of the device list. Click it and it will drop down, as per the screenshot below (click to enlarge).
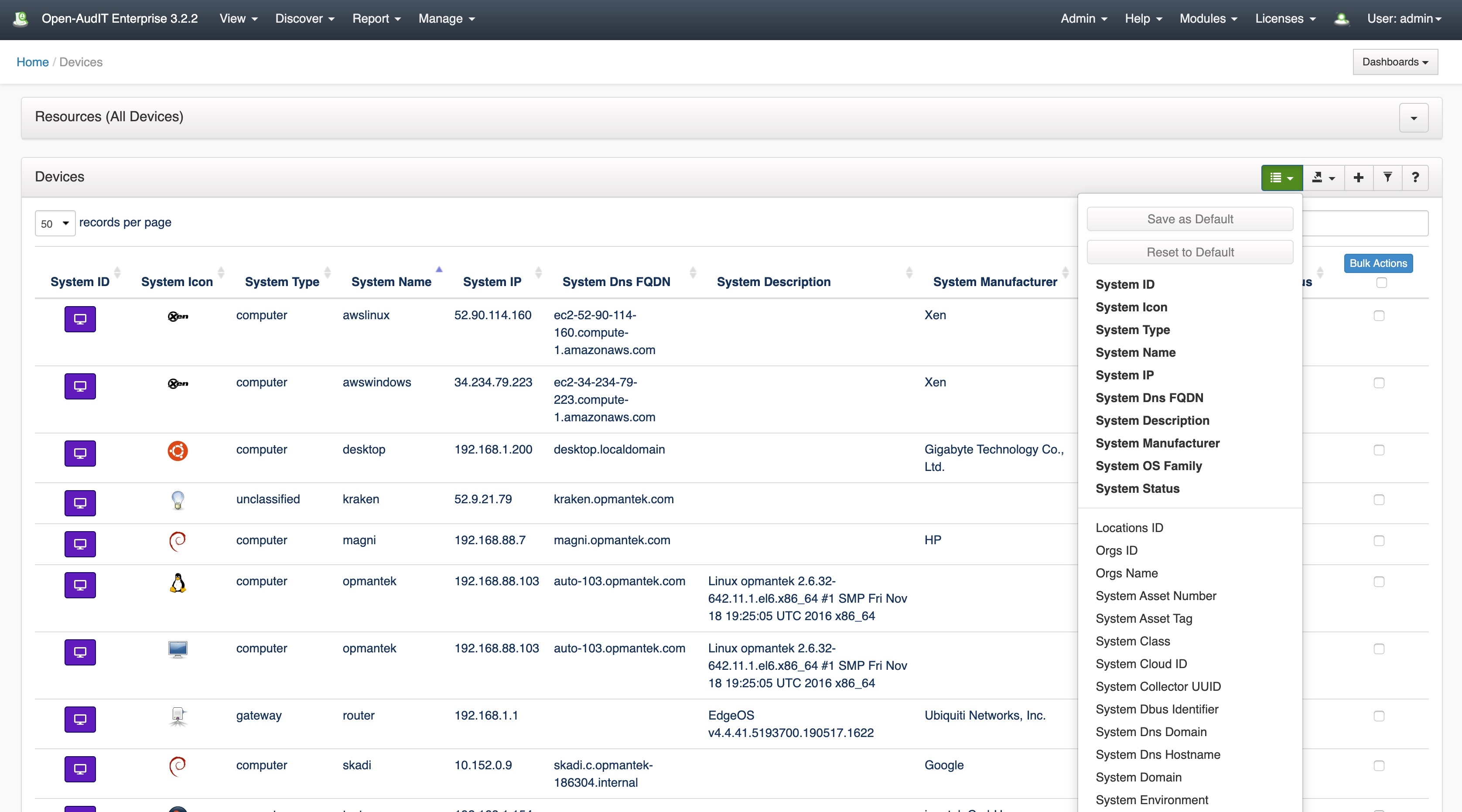
You will see two buttons - "Save as Default" and "Reset to Default". The attributes in bold are currently displayed. If you click one of them, that attribute will disappear. Because you have changed the attribute list, the "Save as Default" button will be enabled. If you then click that, these columns will be your (as in your individual user login) default columns from then on. Once you have saved your default attribute list, if it is different to the default list, the "Reset to Default" button will be enabled. Click it and your attribute list will be reverted to the default, which is stored in the configuration under devices_default_display_columns.
If you click an attribute that is not in bold, it will be added to the column list and the "Save as Default" button activated, as per above. There is no page reload for this. All the data is loaded ahead of time and simply displayed or hidden as required.
In the case where this is causing too much load for your server and / or browser, the default list of attributes to be retrieved are also stored in the configuration under devices_default_retrieve_columns. We do not retrieve every attribute from the system table. You may wish to add or removes attributes from that list as you see fit.
Each user has a default column list (if they're not using the default), so different users can display attributes they care about, without worrying about other users.
This won't replace Queries as we are only displaying attributes form the 'system' table. Queries can display anything you like. But it will enable your users to show the attributes they most care about in their default device listing.
By default (config → devices_default_retrieve_columns) we retrieve the following attributes: system.id, system.uuid, system.name, system.ip, system.hostname, system.dns_hostname, system.domain, system.dns_domain, system.dbus_identifier, system.fqdn, system.dns_fqdn, system.description, system.type, system.icon, system.os_group, system.os_family, system.os_name, system.os_version, system.manufacturer, system.model, system.serial, system.form_factor, system.status, system.environment, system.class, system.function, system.org_id, system.location_id, system.snmp_oid, system.sysDescr, system.sysObjectID, system.sysUpTime, system.sysContact, system.sysName, system.sysLocation, system.first_seen, system.last_seen, system.last_seen_by, system.identification
If you would like another column, just add it in the configuration.
By default (config → devices_default_display_columns) we display the following attributes: system.id, system.icon, system.type, system.name, system.ip, system.dns_fqdn, system.identification, system.description, system.manufacturer, system.os_family, system.status
Oh, and one more thing... In case you were wondering what the panel header with caret titled Resources (All Devices) is in the above screenshot, it drops down to show a selection of the components of devices. Clicking on an icon shows a list of all those things for all devices. On that following list you can click the individual entry and see it's details. This is limited by the config item for XXX rows at a time (the software tables can have 100's of thousands of rows, for example). See below.
For better or worse, all those people that insist on wanting "a list of all my software", this will do exactly that (and any other device component table). In my opinion a list like that is next to useless and you should narrow your scope and write a query, but hey what would I know ![]() This was previously able to be done by specifying the URL /devices?sub_resource=software, but not exposed in the GUI anywhere. Now it is. Have fun!
This was previously able to be done by specifying the URL /devices?sub_resource=software, but not exposed in the GUI anywhere. Now it is. Have fun!


Recently I noticed errors on my Ubuntu 18.04 machine in /var/log/apache2/errors.log that look as below. These may also occur on any other Linux server running Apache and ModSecurity.
[Tue Jan 14 09:58:51.980208 2020] [:error] [pid 8812] [client ::1:48280] [client ::1] ModSecurity: Rule 7f6584a61a50 [id "-"][file "/usr/share/modsecurity-crs/rules/RESPONSE-951-DATA-LEAKAGES-SQL.conf"][line "98"] - Execution error - PCRE limits exceeded (-8): (null). [hostname "localhost"] [uri "/open-audit/index.php/discoveries/26"] [unique_id "Xh0EO9HUUpzELlm@OJLwKwAAAAA"], referer: http://localhost/open-audit/index.php/discoveries/26
These would show multiple times for any requested page.
According to the Atomicorp ModSecurity page here - https://support.atomicorp.com/hc/en-us/articles/360000188468-Rule-execution-error-PCRE-limits-exceeded-8-null- you should increase a couple of limits.
I have edited /etc/modsecurity/modsecurity.conf and set these as recommended below.
SecPcreMatchLimit 250000 SecPcreMatchLimitRecursion 250000
I restarted Apache (sudo systemctl restart apache2) and I have no more warnings in my Apache error log.
Hi Everybody,
With the release of Open-AudIT 3.2.0 comes a major new feature - Rules.
Rules as a collection of entries that essentially say "If the device has an attribute with X, then make the device's other attribute Y.". That may seem abstract, so what about "If the device has an SNMP OID of 1.3.6.1.4.1.9.1.620, then it's a Cisco 1851 router.".
Out of the box we have rules for MAC address prefixes, SNMP manufacturer IDs and all the aforementioned SNMP OIDs previously within Open-AudIT. We also ship various other rules that were previously hard coded. All up, for our first release we're shipping almost 100,000 rules!
"So what?" you say "What does this mean for me?" - well it means that you no longer need to send me your OIDs and device models, for a start. You can create custom Rules that will detect (almost) anything you like and set the appropriate device attribute.
The Rules are processed when a device's details are processed - during discovery and/or upon processing an audit result (hence, they usually run multiple times). Rules conform to the usual priority system - they will override every thing that's not a user input via the GUI. Rules are considered to be YOUR rules. Not something derived from a device. Hence they mean more than (say) something retrieved via SSH or SNMP or WMI. This is because if they don't do what you want YOU CAN CHANGE THEM.
NOTE - At present we cannot delete a rule input or output that contains a /. This is because the framework is parsing the / as part of the URL and returning a 404, even before our code runs. The work-around for this is to delete the Rule itslef, then recreate the inputs and outputs as required. Fortunately inputs and outputs that contain a / are rare (indeed, none exist by default).
Rules have two main sections - inputs and outputs.
Inputs are what is used to detect and match an attribute (or multiple attributes).
Outputs are what is to be set if the inputs match.
Inputs can use several operators to detect a match, not just equals. We can use the following operators:
equals
does not equal
greater than
greater than or equals
less than
less than or equals
like (which is case-insensitive)
not like (again, case insensitive)
in (a list)
not in (again, a list)
starts with
When we test multiple attributes in a single "input", those attributes are ANDed together. You cannot OR them. The below is an example (from the database, stored as JSON).
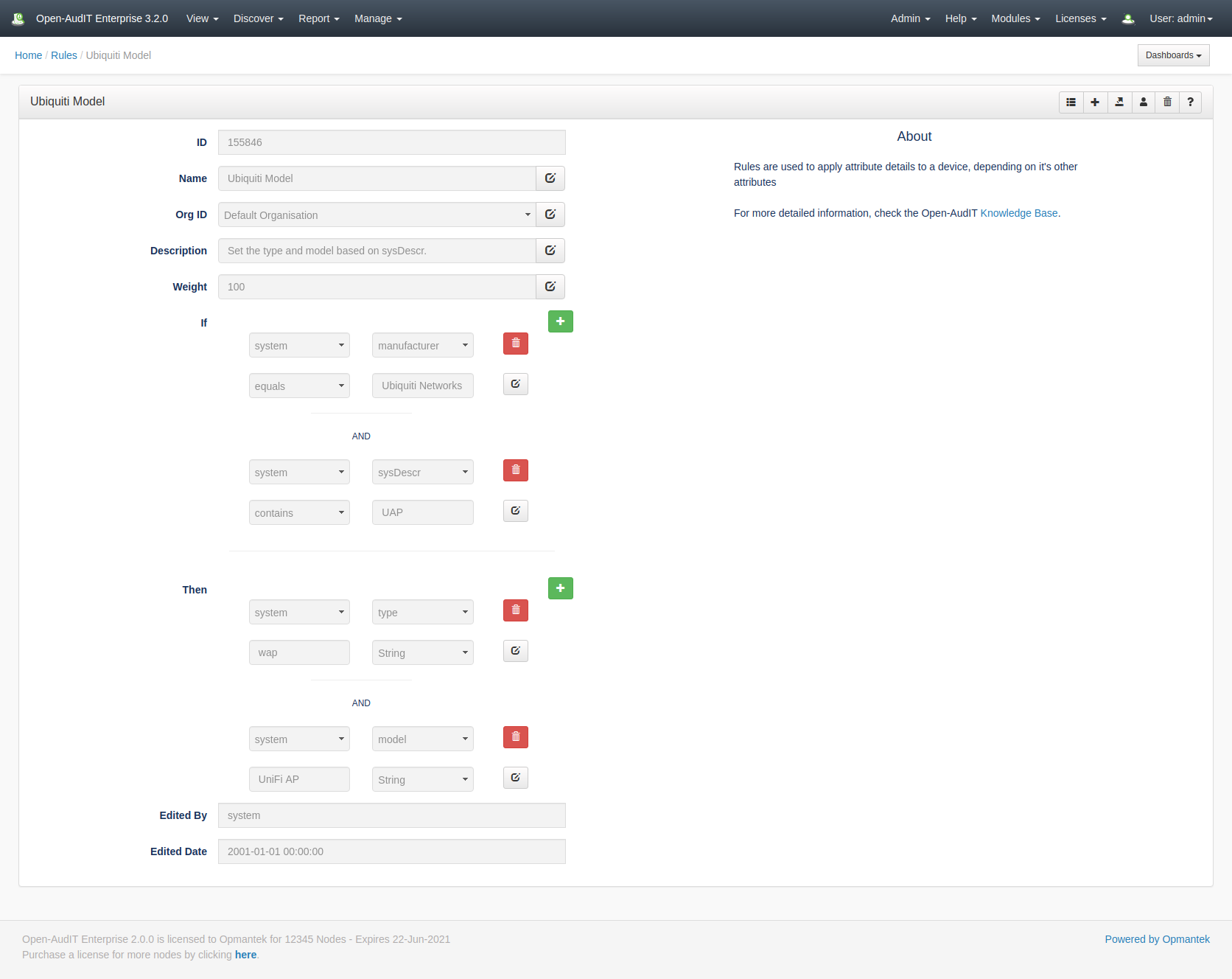
[{"table":"system","attribute":"manufacturer","operator":"eq","value":"Ubiquiti Networks Inc."},{"table":"system","attribute":"sysDescr","operator":"li","value":"UAP"}]
This translates to If system.manufacturer = Ubiquiti Networks Inc. AND system.sysDescr like UAP then we have a match.
The corresponding "output" section from this rules states (again, in JSON from the database):
[{"table":"system","attribute":"type","value":"wap","value_type":"string"},{"table":"system","attribute":"model","value":"UniFi AP","value_type":"string"}]
Which means set the system.type to wap and the system.model to UniFi AP. Outputs can set an attribute using one of three 'types'. a number, text or a timestamp. For a timestamp you have the option of providing a date/time OR leaving it blank and having the system use the current date/time when the Rule is processed.
And don't worry - we wouldn't ask you to write the JSON. The web interface takes care of that for you. Of course, if you're using the API, then the JSON creation is on you :-)
One further item of note is the "weight" attribute we assign Rules. By default it's 100, but any Rules with a higher or lower weight will be run before or after those at weight 100. This provides a way to order the list in which Rules are applied. Mostly you won't need to worry about this, but if required, it's a life-saver.
Rule inputs also don't need to apply only to the "system" table. You can have a Rule on the service table to say if we detect a service named "My Service" then set the device description to "My Service Server" (for a bad example).
At this stage, Rule outputs can only set an attribute (or multiple attributes) on the system table. Custom fields are not supported right now (stay tuned).
The Rules engine is used by Community and available for editing in Professional and Enterprise.
So, what's the downside? Well running 100,000 rules several times does take its toll. I was however pleasantly surprised to see it takes less than 1 second each time all 100,000 Rules are processed. It does however mean more memory is consumed. In my testing it uses about 500MB. You shouldn't need to worry about increasing the PHP memory limit as we do this in code, but you will need to keep an eye on your server. Those users that process many devices AT ONCE may run into memory constraints. In general though, most users shouldn't notice any discernible difference. If you do, first thing to try is giving the server a memory bump. It is a database application after-all, so more memory and fast disk is always the answer :-)
UPDATE - With the release of 3.2.2, we no longer store ~100,000 rules in the database. This was fine on my test device (a core i7, 16GB memory and Samsung 860 NVMe), but in practice was causing customers servers to choke.
As per the Release Notes for 3.2.2 -
So, that was a ride... In testing our new Rules feature worked a treat. In practice, not so much. Most servers (ie, not mine) can't cope with loading the rule set, even if we break it down to smaller chunks, when processing multiple devices. What to do? What to do? Well we've taken a small step back. Rules still exist as a feature, and they still work a treat. But instead of inserting 100,000 Rules into the database, we've split them up into four distinct files and implemented them as code only. Hence, no loading all 100,000 Rules, decoding JSON and running them against a device. Now we just load the files and run the statements. Much, much faster and more memory efficient. No load on MySQL, and hence the CPU also drops. No populating a massive recordset and hence the memory drops. The not so good thing - these are no longer editable in the GUI. But it's not the end of the world. You can still make Rules as you see fit and they will be run after the "default" rules (those in code), hence you can override the "default" rules. So we don't lose much, but we gain a LOT of performance. We also added a few new Rules for Mac Models.
For those curious, the "new" files that replace the Rules are:
| File | Description |
|---|---|
| /open-audit/code_igniter/application/helpers/mac_helper.php | Matches MAC addresses to manufacturers. |
| /open-audit/code_igniter/application/helpers/mac_model_helper.php | Matches Apple manufacturer codes to models (stored in system.manufacturer_code). |
| /open-audit/code_igniter/application/helpers/snmp_model_helper.php | Matches the device's SNMP OID to a model and type. |
| /open-audit/code_igniter/application/helpers/snmp_model_helper.php | Matches the devices's SNMP OID to the manufacturer. |
One final thing of note is the new GUI widget. Because we have almost 100,000 Rules, it's just not feasible to display them all in a list in the GUI. UPDATE - this is still in place, but you will not see all 100,000 Rules in the GUI as now (as per above) most are back in code files. So we don't. We have built a new widget that sits on the panel header and is used to search the Rules. Input anything and the rules name, description, inputs and outputs will be searched and anything matching will be returned. That result-set will still be limited to the default page size (1,000 items), so don't simply search for Cisco and expect to retrieve every Rule (there are 7,828 Cisco Rules by the way).
With this feature we essentially remove the "Tell us your unknown devices" issue as well as provide a powerful tool for you to automatically set attributes of your liking to your devices. Easy.
And one more item - we now have the ability to export a Rule - or anything else for that matter. Exporting an item will provide a JSON object that you can then use for Import. The export button is on each items details page and the import button is on the list page for each collection. With this in place, feel free to send us or post to Questions any Rules or Queries you think others may benefit from.
Happy auditing.
Mark Unwin.

I often utilise Postman to query the Open-AudIT API when developing.
Just using a browser, it's difficult to send anything other than a GET request - but Postman makes it simple to send a POST, PATCH or DELETE as required.
You can get it from https://www.getpostman.com/downloads/ for Windows, Mac and Linux.
Install and start Postman. You can elect to create an account or not. You can also elect to create a new item using the wizard, or just close the modal and jump in. Let's do that ![]()
For the below, my Open-AudIT server is running on 192.168.84.4. You should substitute the IP address of your Open-AudIT server.
Logon
First you need to make a post to /login to get a cookie. Set the dropdown to POST and the URL to http://192.168.84.4/omk/open-audit/logon. Set the header Accept to application/json. Set the Body to form-data and provide the username and password keys, with values as appropriate for your installation. By default it will look as below. Now click the Send button.


You should see the JSON result saying you have been authenticated.
Read
Once that's done, it's time to request some data. Make a GET request to http://192.168.84.4/omk/open-audit/devices and you should get a JSON response containing a list of devices. You can see the start of the JSON in the screenshot below.

Update
What about changing the attribute of an item? Not too difficult. You'll need the ID of the device you want to change, along with the attribute name from the database and an access token.
Access tokens are generated with every request type. You will need a token when submitting a POST or PATCH request. Run another query (a GET is fine, even if no items are returned) and parse the JSON reponse for meta → access_token. Include this in your request body as below.
Attribute names are visible in the application by going to menu → Admin → Database → List Tables and clicking on the "system" table. Let's change the description for our device with ID 14.
You'll need to create a JSON object and assign it to the "data" item to do this. It's not too difficult. Your JSON object should look like below (formatted and indented for easy reading).
{
"data": {
"access_token": "bbc0c85653fdc4b83d108cba7641bfcbbc77586dfb8f32d08973770a90fe",
"id": "14",
"type": "devices",
"attributes": {
"description": "My New Description"
}
}
}
It looks worse than it is. Normally you would use code to do this, so it's a simple two line conversion. Because we're using Postman, we'll have to do it ourselves. A useful site is https://jsonlint.com/
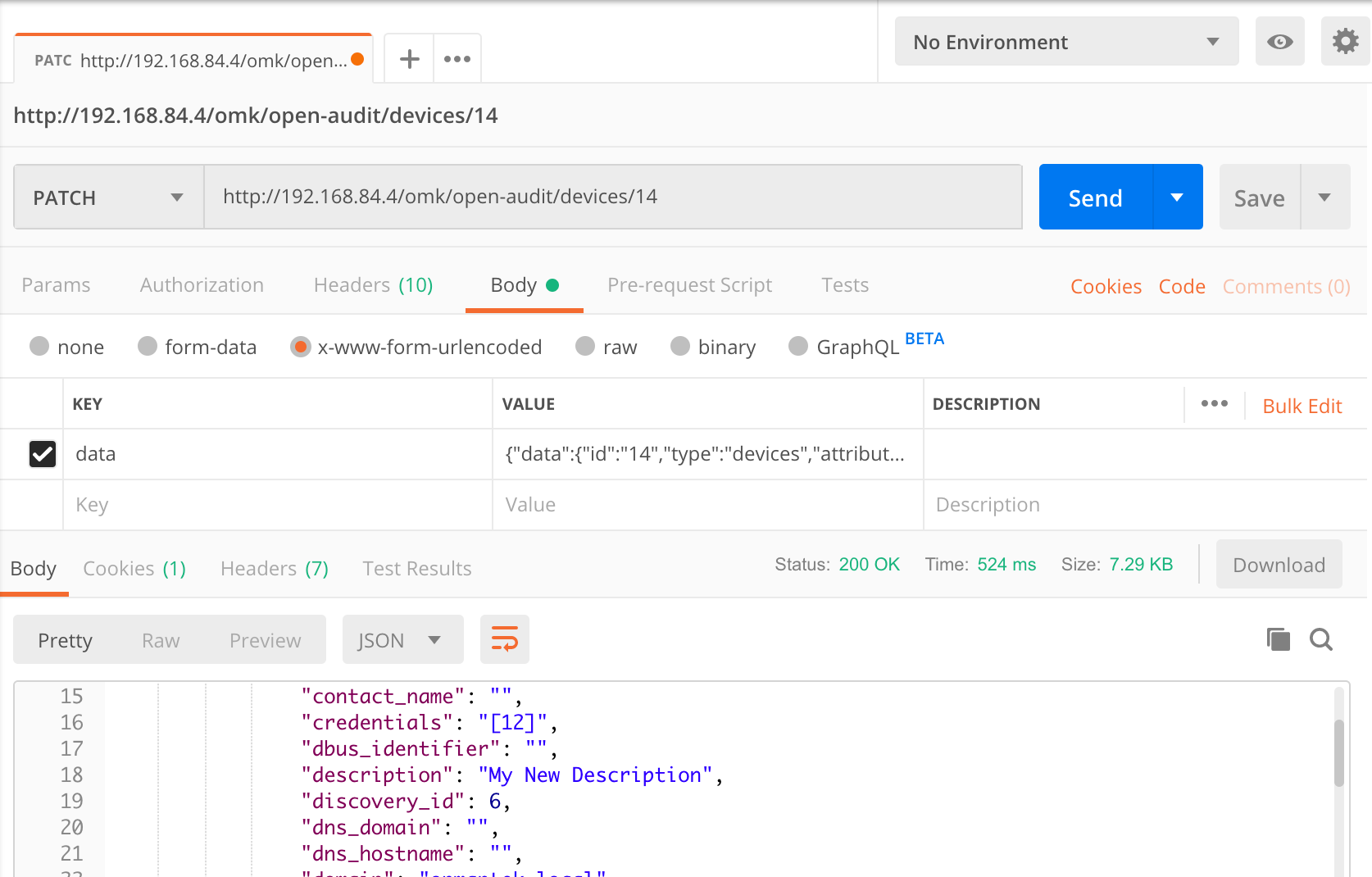
So now you have your payload, let's send it to Open-AudIT. Make a new PATCH request and use the URL http://192.168.84.4/omk/open-audit/devices/14. Supply the data attribute in the body → x-www-form-urlencoded section and hit Send. You should see the request as below.
Delete
Deleting an item is the even easier. Let's delete an Org. In this case, our Org with ID 2. Make a new DELETE request to http://192.168.84.4/omk/open-audit/orgs/2. That's it - easy ![]()
And if we want to read a specific entry, it's just a GET request. Let's get our default Org - ID 1. Just make a GET to http://192.168.84.4/omk/open-audit/orgs/1.
Execute
What about running a query? What's the HTTP verb used to EXECUTE something? There is none ![]() But we'll make do by supplying /execute after the ID. So to execute a query, make a GET request to http://192.168.84.4/omk/open-audit/queries/1/execute. To execute a discovery, task or baseline, use the same format - ID/execute.
But we'll make do by supplying /execute after the ID. So to execute a query, make a GET request to http://192.168.84.4/omk/open-audit/queries/1/execute. To execute a discovery, task or baseline, use the same format - ID/execute.
Create
If we want to create a new item, use a HTTP verb of POST and include an access token. An access token is generated with every request (except logon) and any of the last 20 (by default, settable in the configuration) will be accepted. You should always aim to use the last access token issued.
{
"data": {
"access_token": "bbc0c85653fdc4b83d108cba7641bfcbbc77586dfb8f32d08973770a90fe",
"type": "orgs",
"attributes": {
"name": "My Org",
"parent_id": 1
}
}
}
Output
Remember we always receive the result in JSON as that is in our request header. We could receive it as HTML is we want - just remove that header item. Maybe more useful is a CSV output. Remove the Accept header and change the URL for a GET to http://192.168.84.4/omk/open-audit/queries/1/execute?format=csv. Done - CSV output you can copy and paste into Excel.
It really is that simple. The only one to watch is the PATCH request, because you have to create your own JSON. Just about everything else is quite discoverable. Make sure you check the pages for Collections which detail the request formats. And don't forget The Open-AudIT API page as well.
That makes for a simple and easy way to test the Open-AudIT API.
For more examples, please our new page API Examples for Postman
Onwards and upwards.
Mark Unwin.
With the release of Open-AudIT 3.1.0 we have massively expanded the options around keeping and processing data from devices.
SubSections of a device within Open-AudIT refers to the many tables that hold specific data types - software, netstat ports, processors, memory, disks, users, groups, etc, etc.
These options exist (for now at least) in the Configuration of Open-AudIT. The items of interest are create_change_log* . and delete_noncurrent*.
We previously had these options for a couple of select couple of Subsections, but have expanded these to cover every subsection.
Create Change Logs
The items named create_change_log_* use the database table names to specify which subsection they apply to - so create_change_log_software and create_change_log_memory are both valid examples. You can override ALL items by setting create_change_log to "n" - this will stop any change logs being generated, regardless of the individual table setting. So if a device has a piece of software added (for example), a correspond change log would not be inserted if create_change_log_software was set to "n". This is set to "y" by default. This matches how Open-AudIT has always worked.
Special Items
We have also introduced three special configuration items for Netstat Ports. Because ports above 1024 are mostly designed to be dynamic, we now provide three options to keeping this data. create_change_log_netstat_registered, create_change_log_netstat_well_known and create_change_log_netstat_dynamic. These options correspond to the ports 0-1023, 1024-49151 and 49152-65535.See https://en.wikipedia.org/wiki/List_of_TCP_and_UDP_port_numbers. In particular, Windows DNS servers open a LOT of ports high in the range that are (in my opinion) silly to keep track of, see here and here. By default, only create_change_log_netstat_registered is set to "y". We may add to these options in the future for other subsection, if required.
Delete NonCurrent Items
Along similar lines, the configuration items for delete_noncurrent* use the database table names to specify which subsection they apply to. If set to "y", then no historical entries will be kept for that table, only the "current" items as at the last audit (or discovery). Again, these individual items can be overridden by the global "delete_noncurrent" item. If set to "y", it will remove all noncurrent items from all tables. This is set to "n" by default. This matches how Open-AudIT has always worked.
Hopefully these options provide some customisability for you to only keep the data you actually need.
Onwards and upwards.
Mark Unwin.
After some extensive code rework, Open-AudIT 3.1.0 has been released for both Linux and Windows.
The Release Notes for Open-AudIT v3.1.0 provide specific details, but at a high level we've been changing the codebase to allow us to provide Open-AudIT Cloud in the near future. A hosted version of Open-AudIT that is always up to date, gets the latest code before regular releases, gets patches and bug fixies straight away and minimises the amount of infrastructure on premise required to get Open-AudIT up and running.
There have also been improvements around The Default Network Address, example device data, audit subsection processing, logging improvements, bug fixes and more.
I hope you find Open-AudIT as useful as I do.
Mark Unwin.
With the new release of Open-AudIT 3.1.0, we no longer require the configuration item "default"network"address" to be set for Discoveries. It is still required for the "Audit My PC" functionality, but we hope to minimise this dependance going forward as well.
Why was Default Network Address required?
Initially when we ran a discovery, on both Linux and Windows, we ran the audit script in such a way that it needed to know where to submit it's result. What URL should it use - hence the requirement for the configuration item. A while back now we changed how Discoveries ran under Linux, removing this requirement.
Linux
Linux discoveries send the audit script to the target, run it with a flag of "submit_online = n" and "create_file = w". So do not submit the result to the server, create a file and output the filename to the console. The server waits for the script to finish and captures the console output. It now has the filename of the result on the target system. It copies the result from the target to itself and processes it. All good so far.
Windows
We could never make Windows work this way. The account we use for Apache is the standard "Local System" account. This account has no access to network resources. Hence it cannot simply copy the script to or from a target PC. This was always a pain because the Linux way of running the Discovery was so much better and cleaner. After some (more) research we realised we can use network resources via "net use" - we simply don't assign a drive letter. Yay! So Windows now can copy the audit script to the target, run it, wait for the console output and then copy the result file back and process it, just like Linux.
NOTE - If you are seeing issues copying the scripts when using the default "Local System" account, please change the Apache service to use another assount. This account does not need any special access (as credentials are supplied for devices in Open-AudIT itself), it just needs "network" access.
Finally!
All that is a long explanation for "we don't need the default network address set". That's one less item a user needs to worry about.
We do still have the requirement to set the default network address for the functionality of the "Audit My PC" on the login page. We have plans to minimise this as well - if you can view the login page, we can use the request URL and work out what the default network address should be.
For now it's still required (as at 3.1.0), but look for it to be removed as a requirement in a near future release.
One step at a time, we're trying to make Open-AudIT as easy to use as possible.
Onwards and upwards.
Mark Unwin.
After a long and interesting v2 series, we welcome v3 into the world!
Why v3 you ask? Well, with the recent improvements around discovery scan options and the resulting dramatic increase in discovery times along with the Windows version finally updating its XamppLite package to the latest full Xampp install, we thought it warranted the version increase.
What's changed? See Discovery Scan Options and the Release Notes for Open-AudIT v3.0.0.
Windows users have been left waiting lately, so you might also want to check the release notes for Release Notes for Open-AudIT v2.3.2 and Release Notes for Open-AudIT v2.3.3
We have introduced a new field for your devices called "identification" along with a new device type of "unclassified". This is used when we have some information about a device, but have not been able to talk to it using SNMP, WMI or SSH. So if we have a MAC address, or we know port X is open, then we know something and provide a type of unclassified. We populate the identification field with what we know. In the case where we literally have an IP and possibly a DNS hostname, the device will remain unknown in type. You can see these details on the Devices section of the Discoveries screen. This should help point you in the right direction to identifiying a device, rather than us throwing our hands in the air and saying "we couldn't talk to it, so it's unknown".
The new Discovery Scan Options are fully customisable for Enterprise users, choosable on a per discovery basis for Professional users and selectable on an install basis for Community users. We set the default to use UltraFast options and the increase in speed (especially on Linux servers) is, to put it midly, massive. We have genuine reports of a customer scanning their /22 and having the scan time drop from 29 hours to under 10 minutes. That is not a lie or exaggeration. I know it sounds hard to believe. Obviously there are surrounding conditions - network speed, device speed, reduced Nmap ports reporting, etc - but the result is genuine. To say we're happy with the performance is understating it quite a lot ![]()
We have finally managed to move Windows users from XamppLite to full Xampp. This wasn't without it's challenges, the largest being the PHP changes from 5.3 to 7.3 and encryption functions. In order to facilitate this, we use the existing 2.x install to export the encrypted credentials for credentials, device specific credentials, clouds and LDAP servers to a file, upgrade Xampp and Open-AudIT, then on the database schema upgrade, use the generated text file to encrypt the credentials and update the database entries. Once that's done and you're happy everything has worked, you can delete the file c:\xampplite\open-audit\migrate.json (we do not delete this file automatically). We also do not remove the old XamppLite installation. That is left for the user to decide to delete it at a time when they're happy with their new Open-AudIT 3.0.0 install.
Open-AudIT has never been easier to use, faster or more customisable than it is right now.
If you haven't upgraded, get on board!
Introduction
As at Open-AudIT 2.3.2 and later, we have introduced some easy to use and extremely powerful options for discovering devices. These options centre around directing Nmap on how to discover devices.
We have grouped these options into what we're calling Discovery Scan Options. We ship seven different groups of options (items) by default that cover the common use-cases.
This benefits Community, Professional and Enterprise customers.
Feature Availability
Feature availability is dependent on license type as per the table below.
| Feature | Community | Professional | Enterprise |
|---|---|---|---|
| Match Rules - set default for all discoveries | y | y | y |
| Discovery Scan Options - set default for all discoveries | y | y | y |
| Discovery Scan Options - read | y | y | |
| Discovery Scan Options - set per discovery | y | y | |
| Discovery Scan Options - create, read, update, delete | y | ||
| Discovery Scan Options - Custom per Discovery | y | ||
| Discovery Scan Options - Exclude IP, range, subnet per discovery | y | ||
| Discovery Scan Options - Exclude ports per discovery | y | ||
| Discovery Scan Options - Set device timeout, per discovery | y | ||
| Discovery Scan Options - Custom SSH port per discovery | y | ||
| Match Rules - set per discovery | y |
Discovery Scan Types
The Discovery Scan Options we ship are detailed in the table below. As above, Enterprise users can create more of these or edit the shipped items.
| Attribute | UltraFast | SuperFast | Fast | Medium (Classic)1 | Medium | Slow | UltraSlow |
|---|---|---|---|---|---|---|---|
| Approximate time in seconds for remote IP scan | 1 | 5 | 40 | 90 | 100 | 240 | 1200 |
| Must Respond to Ping | y | y | y | n | y | y | n |
| Use Service Version Detection | n | n | n | n | n | y | y |
| Consider Filtered Ports as Open | n | n | n | y | n | y | y |
| Timing | T4 | T4 | T4 | T4 | T4 | T3 | T2 |
| Top Nmap TCP Ports | 10 | 100 | 1000 | 1000 | 1000 | 1000 | |
| Top Nmap UDP Ports | 10 | 100 | 100 | 100 | 1000 | ||
| Custom TCP Ports | 22,135,62078 | 62078 | 62078 | 62078 | 62078 | 62078 | 62078 |
| Custom UDP Ports | 161 | 161 | |||||
| Exclude TCP Ports | |||||||
| Exclude UDP Ports | |||||||
| Timeout per Host | |||||||
| Exclude IP (address, range, subnet) | |||||||
| Custom SSH Port |
1The item for Medium (Classic) is similar to the Nmap for Discovery setting available in Open-AudIT 2.3.2.
Check the wiki here for a deeper look at Discovery Scan Options.
Example Scanning Improvement
We have a customer who is running discovery on a /22. The scan time to complete when using the original (hard set) options, prior to 2.3.2 was 29 hours. Using 2.3.2's UltraFast option, that scan now takes less than 10 minutes. To say they are impressed would be an understatement! They are now left with a smaller set of unknown devices that they can run a more detailed audit against. And remember, if the audited device is a computer, you will have a list of open ports derived from Netstat, anyway - possibly saving another audit cycle.
Use Cases
Handling Duplicate Serials
Recently we had cause to scan a subnet that was made up of virtual Cisco networking devices. These devices all happened to have identical serial numbers. Using the Match Rules per Discovery (available to Enterprise users) we were able to tweak the ruleset for this discovery only, without affecting other discoveries that rely upon matching a serial number. This ability solved a long-standing issue of working around a less than ideal setup on a network. A serial number, by definition, should be unique.
Filtered Ports
Networks respond differently depending on how they're configured. Some routers and/or firewalls can respond "on behalf" of IPs on the other side of their interfaces to the Open-AudIT Server. It is quite common to see Nmap report a probe for SNMP (UDP port 161) to respond as open|filtered for devices that do and do not exist. This is misleading as there is no device at that IP, yet it ends up with a device entry in the database. 99.9% of the time, it is not Open-AudIT, nor even Nmap, but the network causing this issue. Now that we have the options to treat open|filtered ports as either open or closed, we can eliminate a lot of this confusion. Enterprise users even have the option to change this on a per discovery basis (more than just using the Medium (Classic) item, as above).
Discovery Enterprise Options
The screenshot below is the Open-AudIT discovery page where all the audit configuration is set. I've added ample notes in the page explaining all the options making the tool easy to use for less technical staff.
Click to enlarge.

Check the wiki for a more detailed explanation about Discoveries
Display Improvements
As well as the functional improvements to discovery, we have also revised the Discovery Details page. We have sections for Summary, Details, Devices, Logs and IP Addresses. The Devices section, in particular, is now much more useful. We have added a new type of Unclassified to the list and we use this when we have more than just an IP and/or name for the device. For instance, we may know it's IP, name and the fact that it has port 135 open. This at least is a good indication that the device is likely a Windows machine. So we know "something". More than just "there is something at this IP". That is now an Unclassified device. We still support Unknown devices as always - for those devices we really know nothing about. An example of this screen is below. We also provide a quick link to creating credentials when a service (SSH, WMI, SNMP) has been identified, but we were not able to authenticate to it.
We think these display improvements will go a long way to assisting you to remove any Unknown or Unclassified devices that are on your network.
Click to enlarge.

Wrap Up
This new functionality makes Open-AudIT a powerful and easy to use discovery solution while providing great flexibility for advanced users.
I hope you enjoy the new features as much as our test customers and I do.
Mark Unwin.
We've released version 2.2.0 of Open-AudIT today. As outlined on the release notes page, this release concentrates on the new Dashboards and Widgets features. Open-AudIT can be downloaded here.
We've released version 2.1.1 of Open-AudIT today. As outlined on the release notes page, this is primarily a maintenance release with no new features. Open-AudIT can be downloaded here.